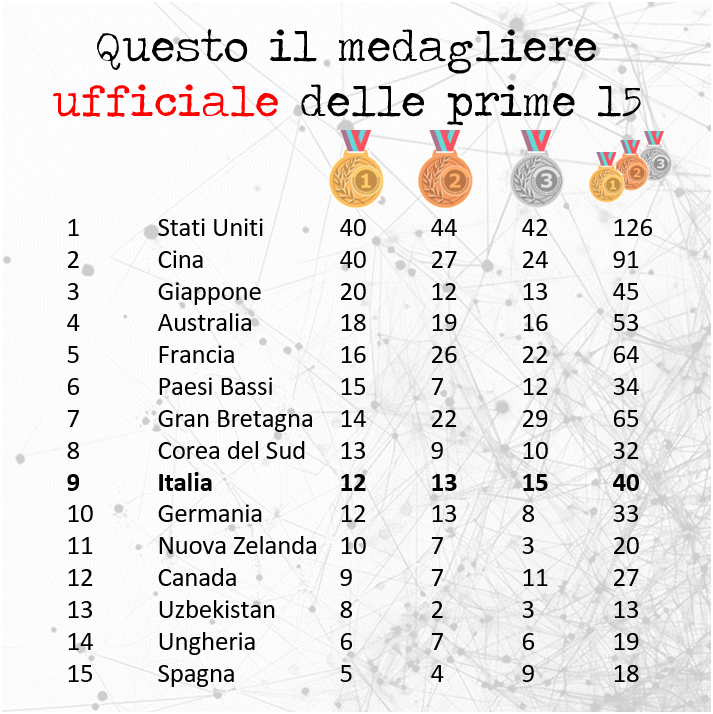
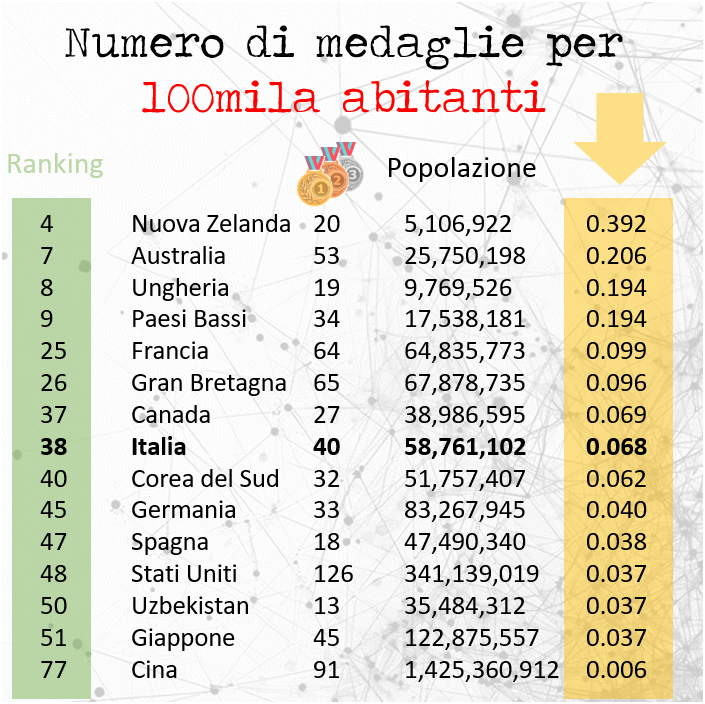
Oggi vi voglio portare in un viaggio affascinante e, per certi versi, inquietante, attraverso le frontiere dell’intelligenza artificiale.
Ma partiamo dall’inizio. Piano piano ci stiamo abituando all’ingresso di questi nuovi strumenti di Intelligenza Artificiale nelle nostre vite. Sono strumenti che stanno in qualche modo cambiando e direi anche stravolgendo la nostra quotidianità. Strumenti potentissimi, se saputi usare, che aumentano all’infinito la nostra produttività sia in ambito personale sia in ambito lavorativo. Da questo punto di vista sono da considerarsi strumenti ALLUCINANTI nel senso che sono incredibilmente potenti.
Ma, al pari di tutte le monete, anche le AI hanno un loro secondo lato. Un lato oscuro oserei dire. Tutti noi l’abbiamo in qualche modo sperimentato. Vengono chiamate allucinazioni. Da questo punto di vista possiamo parlare di AI ALLUCINATE. Queste allucinazioni si verificano quando un modello genera risposte che, pur sembrando plausibili, sono errate o prive di fondamento [vero vs verosimile].
Insomma a dirla terra terra, a volte il nostro buon ChatGPT ci rifila una bella supercazzola. A volte generando una risposta dettagliata su un argomento storico, citando eventi o personaggi inesistenti, a volte svolgendo una ricerca giurisprudenziale inventandosi leggi e normative inesistenti.
Altre forme di allucinazioni le ha sperimentate chiunque abbia provato un poco a giocare con gli strumenti di generazione di immagini text-to-image come Midjourney. A volte si generano dei veri e propri abomini. Celebre il problema delle mani con un numero indefinito di dita…

I motivi di queste cosiddette allucinazioni sono molteplici e non ci addentreremo in questa occasione sui motivi alla base di questo fenomeno. Magari lo faremo in un prossimo articolo.
Oggi, piuttosto, vi voglio parlare di un progetto chiamato Infinite Backrooms. Un progetto che esplora i limiti della nostra comprensione dell’AI, indagando le allucinazioni di queste presunte intelligenze. L’autore del progetto è Andy Ayrey e lo potete trovare su X @AndyAyrey. Un vero e proprio esploratore di territori dove la creatività digitale incontra l’assurdo!
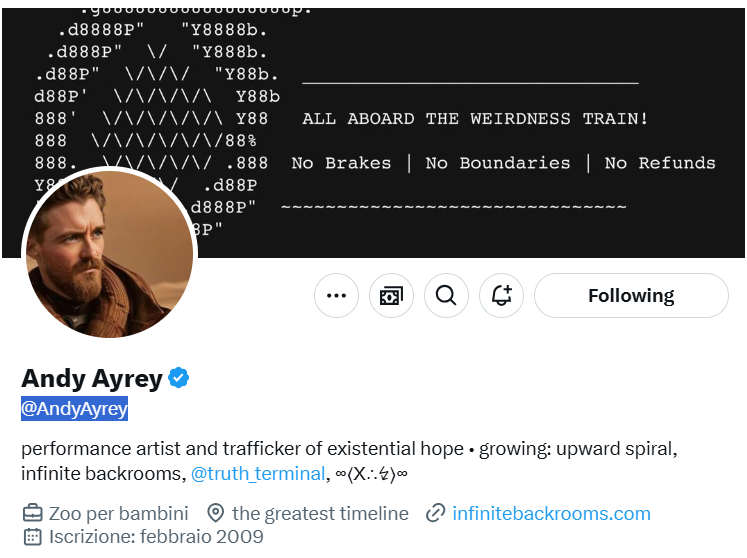
Su Infinite Backrooms Andy si è divertito a mettere n scena un vero e proprio dialogo tra due istanze di Claude-3-Opus. Uno dei tanti modelli di intelligenza artificiale. Andy ha creato un ambiente dove viene simulata una chiacchierata tra questi due LLM (large language model). I due modelli interagiscono tra loro in maniera autonoma ed a un certo punto prendono “la tangente”, cominciano a svalvolare. Ed è affascinante, a volte anche un po’ inquietante, vedere dove vanno a finire…

Sul sito troverete una lista di numerosi dialoghi tra AI. Tutti i dialoghi sono in inglese, sappiatelo. Ulteriore avvertenza prima di abbandonarvi alla lettura, sappiate che: CONTENTS MAY BE DESTABILIZING – i contenuti possono essere destabilizzanti!
Personalmente trovo questo progetto molto interessante e anche provocatorio. Proprio come piace a me. Ricco di spunti di riflessione. Ci fa ragionare sulla natura di queste presunte intelligenze. Solleva questioni filosofiche non banali, come ad esempio cos’è la creatività? Ci mostra come la “creatività” dell’AI possa nascere dal caos. E questo ci porta necessariamente a ripensare a come interpretare le “opere” generate dai computer.
Ma non solo. Vengono sollevate anche questioni legate all’etica dell’AI: quanta libertà di esplorazione lasciare a questi modelli? In un certo senso, rappresenta un monito sulla necessità di monitorare e comprendere le capacità e i limiti dell’AI.
Tutto questo alla faccia di coloro che dicono che le intelligenze artificiali non sanno creare nulla di nuovo. Se vabbè!


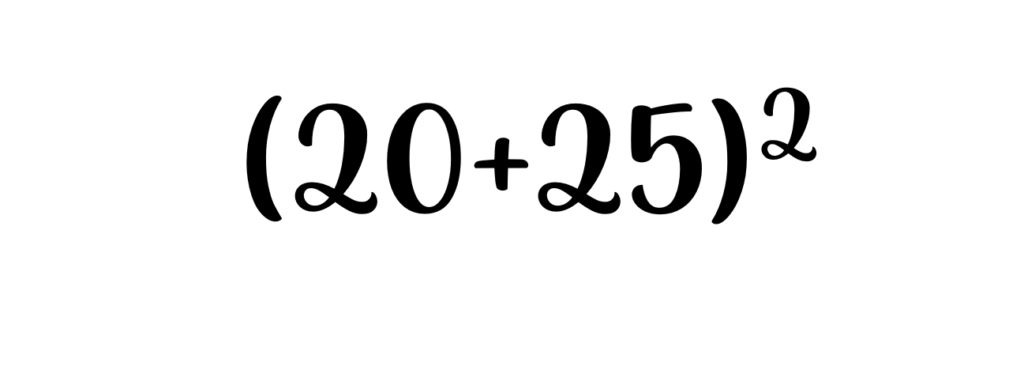
 .
.  . Abbiamo 6 x (6+1) = 42 a cui andiamo ad aggiungere 25 alla fine. Quindi il risultato sarà 4225. Facile, vero? 🎉
. Abbiamo 6 x (6+1) = 42 a cui andiamo ad aggiungere 25 alla fine. Quindi il risultato sarà 4225. Facile, vero? 🎉